[Review] SnapMix: Semantically Proportional Mixing for Augmenting Fine-grained Data
Image classification (특히 fine-grained image classification) 문제에서 사용되는 augmentation 중 mixing labels은 그 유효성이 입증되어 여러 방법들이 제안되었다. MixUp과 CutMix가 대표적인 방법들로 MixUp은 이미지를 선형결합하여 하나의 fused image with mixing labels를 만드는 것이고 CutMix는 특정 비율의 영역을 다른 이미지에 임의로 할당하여 compound image with mixing labels를 만드는 것이 그들의 요지이다.
Shaoli Huang 외 2명은 fine-grained image classification에 상기한 두 방법이 분명 유효함을 인정하였지만 아직까지도 문제점을 가지고 있다고 지적했다.
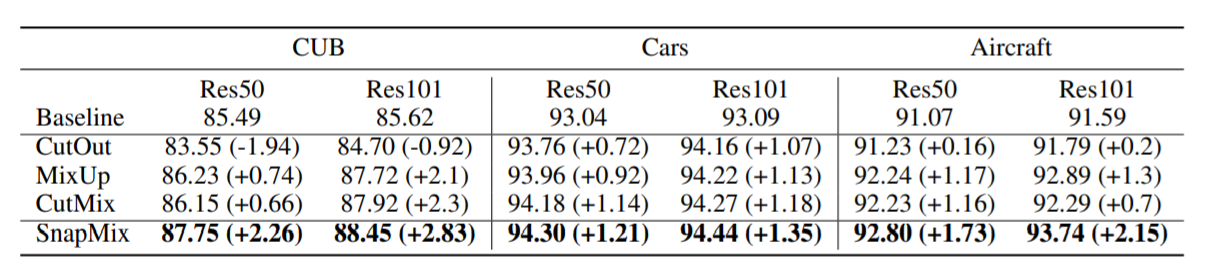
Fine-grained image classification은 기존 개와 고양이를 구분하는 image classificaiton과 다르게 개의 범주 안에서 종을 구분하는 형태의 task를 지칭한다. 따라서 어쩌면 정말 협소한 영역에서 class 구분이 갈리는 경우가 왕왕 발생할 수 있다. 이 때 CutMix의 경우 단순 픽셀 영역을 기준으로 multi labels의 proportion을 결정하기 때문에 되려 noisy label가 발생할 여지가 있다는 것이 그들의 주장이다. 아래 예시에서 두 새의 사진을 CutMix하여 하나의 compound image with mixing labels를 만든다고 하자. 이 때 왼쪽의 검정 새는 붉은 어깨와 황색 익대(wing bar)가 특징적이다. 그러나 오른쪽 새와 합성이 이루어진 다음에도 아직도 남은 영역의 넓이가 ‘잘려졌으나 특징적인 영역’보다 넓기 때문에 label은 [검정 새: 0.6, 노랑 새: 0.4]가 된다. 그 결과 해당 mixing labels는 noisy labels일 가능성이 크다.
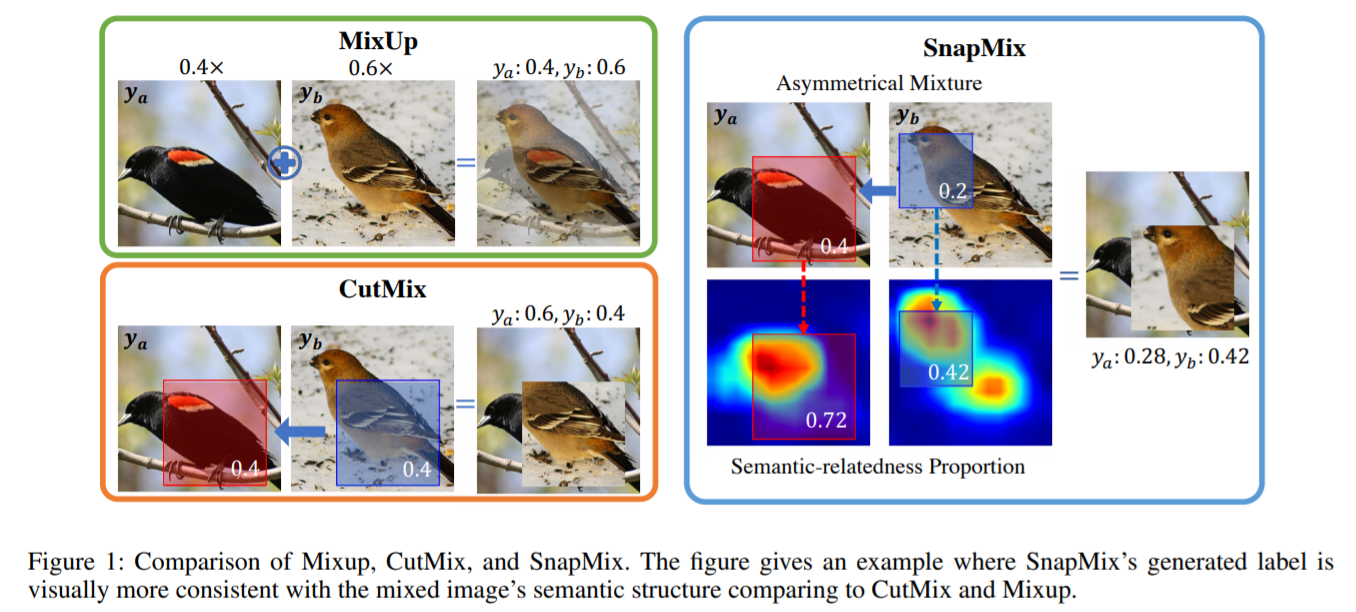
그들이 제시한 Semantically Proportional Mixing for Augmenting Fine-grained Data, 즉 SnapMix는 class activation map을 기준으로 compound image 및 mixing labels를 만들기 때문에 앞서 말한 기법들이 사용하는 labels의 선형 결합보다 훨씬 합리적인 augmentation이 가능하다고 주장했다. SnapMix augmentation은 다음과 같은 과정을 거친다.
- Mixing images (아래 그림의 Random Boxes Generation 및 Box Masking and Transforming에 해당)
여기서 \(I'\), \(I_{a}\), \(I_{b}\)는 각각 compound image, image \(a\), image \(b\)를 의미한다. \(M_{a, b}\)는 image 내 random mask를 결정하는 binary matrix, 그리고 \(T_{\theta}\)는 \(I_{b}\)에서 추출한 mask를 \(I_{a}\)에 합성하기 위해 적용하는 transformation이다.
- Label generation (아래 그림의 Class Activation Mapping 및 Semantic Percentage Maps에 해당)
Semantic Percentage Maps(SPM)는 위의 compound image의 label values를 결정하기 위한 가장 중요한 근거이다. 이 SPM은 Class Activation Map으로 결정할 수 있다. Network의 가장 마지막 convolutional layer를 통과한 \(d\)개의 features \(\{F\}\)를 classifier의 \(d\)개의 가중치 \(\{\omega\}\)와 곱하여 정규화하면 SPM을 얻을 수 있다.
\[S(I_{i}) = \frac{CAM(I_{i})}{\sum_{p}^{h \times w}CAM(I_{i})}\] \[CAM(I_{i}) = \Phi(\sum_{l=0}^{d}\omega_{y_{i}}^{l}F_{l}(I_{i}))\]여기서 \(\Phi\)는 input image와 크기를 맞추기 위한 upsampling operator이다. 이제 label weights \(\rho_{a}\), \(\rho_{b}\)는 이 SPM과 앞서 정의한 binary matrix로 구할 수 있게 된다.
\[\rho_{a} = 1 - \sum_{p}^{h \times w}(M_{a} \odot S(I_{a}))\] \[\rho_{b} = \sum_{p}^{h \times w}(M_{b} \odot S(I_{b}))\]이러한 Segentation Percentage Map을 활용한 mixing augmentation은 noisy labels를 억제할 수 있는 장점을 가진다. 한 가지 특기할 점은 종전의 방식들과는 다르게 \(\rho_{a}\)와 \(\rho_{b}\)가 독립적인 관계이기 때문에 반드시 두 labels의 합이 1일 필요는 없다.
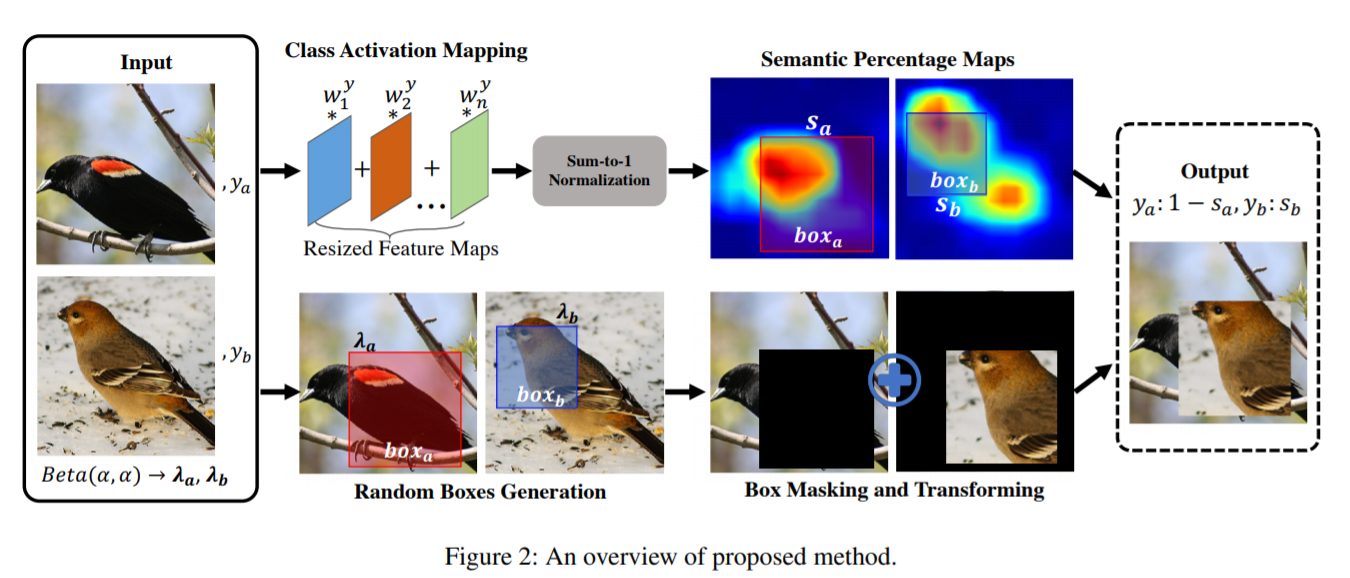
아래 표는 fine-grained image classification에서 자주 사용되는 dataset인 CUB-200-2011 (Wah et al. 2011, 이하 CUB), Stanford-Cars (Krause et al. 2013, 이하 Cars), and FGVC-Aircraft (Maji et al. 2013, 이하 Aircraft)에 대한 performance 비교 표이다. 비교한 augmentation은 CutOut, MixUp, CutMix, SnapMix이다. 표에서 명시되었듯 의미있는 성능 향상이 있는 것으로 보여진다.