
[Review] Scalable Active Learning for Object Detection
Machine learning의 supervised learning에서는 그 무엇보다도 labeled training data가 가장 중요하다. 물론 인터넷에 공개되어 있는 풍부한 open dataset을 우선적으로 활용하는 것을 고려해봄직 하나 특수한 목적의 custom algorithm 개발에서는 unlabeled data가 압도적으로 많고 이를 labeling하는 것에 인력과 시간이 많이 소비된다. 확보한 모든 unlabeled data를 학습하는 것이 가장 이상적이나 앞서 언급한 인력과 시간의 소모를 무시할 수 없으며 현 algorithm에서 추가로 어떤 data를 학습하는 것이 성능을 높일 수 있는지 최근 들어 연구가 진행되고 있다. 이러한 일련의 연구 분야를 active learining이라고 한다. 본 시리즈에서는 computer vision의 대표적인 영역, image classification, object detection, semantic segmentation 중에서 object detection에 대한 active learning에 대해 집중적으로 다뤄볼 것이며 가벼운 모델을 바탕으로 그 유효성을 확인해 볼 것이다. 본 포스트에서는 실험에 주로 참고가 된 다음 논문[1]을 리뷰할 것이다.
이하 전반적인 내용은 논문을 따라가나 수식에 대한 명확하지 않은 부분에 대해서는 수정을 했다. 또한 보충 설명이 필요한 부분은 임의로 추가했다.
Introduction
Active learning
이미 어느 정도 학습된 network에 추가 images를 학습한다고 하자. 물론 잘 정제된 images라면 임의로 학습을 해도 어느 정도의 accuracy가 오를 것이다. 하지만 한정된 시간에 효율적인 성능 향상을 목표로 한다면 어떤 image를 우선적으로 labeling하여 학습할 지 우선순위를 정하는 것이 임의로 학습하는 것보다 훨씬 나을 것이다. 이 때 추가 dataset에서 우선순위를 정하는 척도는 바로 uncertainty로, 학습된 network가 가장 판정하기 불확실하다고 인식되는 것 먼저 학습을 진행시키는 것이 타당하다고 자연스럽게 도출이 된다. Active learning에 대한 연구는 바로 보다 합리적으로 uncertainty를 계산하는 것에 목적을 두고 있다.
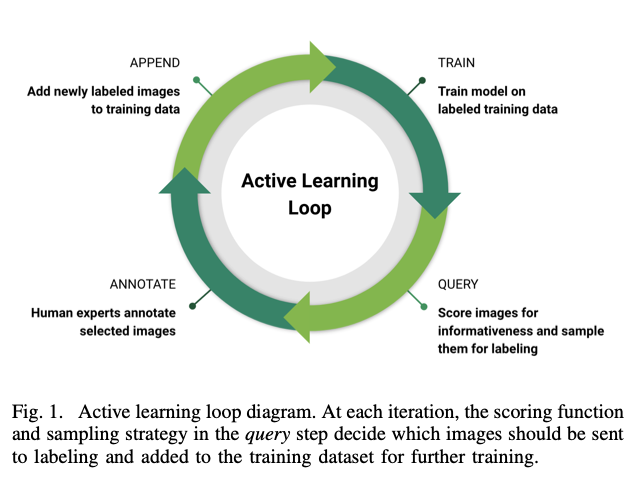
Active learning for computer vision
Computer vision의 어느 연구도 대부분 비슷하지만 active learning에 대한 연구는 image classification에 집중되어 있다. Object detection이나 semantic segmentation에서는 아직 충분한 진전은 이루어지지 않았다. Image classification에서의 active learning에서는 각 class에 대해 도출된 probability를 이용하여 uncertainty를 계산한 후(계산하는 함수를 acquisition function, scoring function이라고 한다.) 상위의 uncertainty를 우선순위에 두는 방법을 사용하고 있는데 object detection과 semantic segmentation에서도 이와 대응되는 아이디어를 활용하고 있다.
Scalable active learning for object detection
본 section에서는 두 가지 개념에 대해 서술한다. 첫 번째는 scoring function으로 uncertainty를 계산하는 방법, 두 번째는 uncertainty로 정렬한 우선순위를 sampling하는 방법이다.
Scoring function
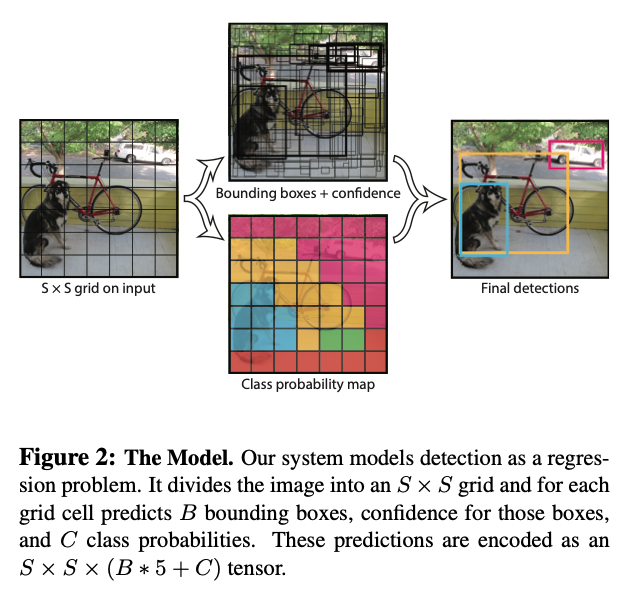
Object detection은 기본적으로 R-CNN과 같은 2-stage detector, SSD, YOLO와 같은 1-stage detector로 나눌 수 있다. 본 subsection은 SSD, YOLO와 같이 postprocessing 직전에 나오는 class probability map, confidence score map과 같은 output map을 사용하는 것을 전제로 한다. YOLO의 경우, 각 grid 별로 bounding box score 및 class probability를 mapping할 수 있으며 그 개수는 anchor box의 개수 \(N\) 및 class의 개수 \(C\)에 따라 달라진다 (즉 class probability map은 \(N \times C\) 개, confidence score map은 \(N\) 개).
- Entropy
Class probability map을 기준으로 각 grid position \(\mathbf{p}\)에서의 \(c\)th class에 대한 probability를 \(p_{c} \equiv P_{c}(\mathbf{p})\)로 정의한다. Class probability에 대한 불확실성을 entropy로 계산하면 다음과 같이 정의할 수 있다.
\[H(p_{c}) = p_{c}\ln p_{c} + (1-p_{c})\ln(1-p_{c})\]- Mutual Information (MI)
Mutual information은 두 확률 변수의 상호 의존성을 판단하는 방법으로 이번 경우에는 각 position의 class probability와 전체 ensemble의 disagreement를 측정하는 용도로 도입한다. 전체 ensemble의 average probability를 다음과 같이 정의한다.
\[\bar{p}_{c} \equiv \frac{1}{|E|}\sum_{e\in E}p_{c}^{(e)}\]따라서 mutual information은 다음과 같이 표현할 수 있다.
\[MI(p_{c}) = H(\bar{p}_{c}) - \frac{1}{|E|}\sum_{e\in E}H(p_{c}^{(e)})\]- Gradient of the output layer (Grad)
BADGE(Batch Active learning by Diverse Gradient Embeddings)라고 불리며 각각 predicted label과 groundtruth label의 gradient embeddings을 구해서 uncertainty를 계산하는 방법이다. (BADGE[3]에 대해서는 추후 다룰 예정이다)
- Bounding boxes with confidence (Det-Ent)
저자들은 entropy(or mutual information)을 계산할 때 사용하는 probability에 대해 object detector에서 최종적으로 나오는 bounding box score with class 또한 활용될 수 있다고 주장했다. 본 시리즈에서도 해당 method를 사용할 것이다.
Score Aggregation
Output map의 각 position \(\mathbf{p}\) 에서 계산한 uncertainty를 계산했으나 이를 aggregate하여 image당 하나의 score로 표현해야 한다. Aggregation method에 대해서는 maximum, average 그리고 sum이 있으며[4] maximum인 경우
\[s = \max_{c\in C}\max_{\mathbf{p}}I(p_{c})\]로 각 image당 score \(s\)를 계산할 수 있다.
Reference
[1] E. Haussmann et al., Scalable Active Learning for Object Detection, arXiv:2004.04699 (2020)
[2] J. Redmon et al., You Only Look Once: Unified, Real-Time Object Detection, arXiv:1506.02640 (2016)
[4] C-A Brust et al., Active Learning for Deep Object Detection, arXiv:1809.09875 (2018)